こんにちは、編集長の白石です。HTML5 Experts.jp新春企画「Webの未来を語ろう 2017」の第二弾は、メディア編です。
2016年は、アメリカ大統領選やキュレーションメディアなど、メディアをめぐる大きな事件と、それをめぐる議論が大変活発だったように思います。私も一応メディア運営をしている身として、一方ならぬ興味を持ってそれらの事件を眺めていました(HTML5 Experts.jpは、そういうのとあんまり関わりないメディアですが…)。
ということで、今回はWebメディアに精通しているゲストの方々にお越しいただき、メディアの未来について語り合いました。とはいえここはHTML5 Experts.jp、テック系メディアですので、テクノロジーにも踏み込んだ議論とさせていただきました。

今回はゲストの方々を集めて誌上座談会としようと思ったのですが、あまりにゲストが豪華になってしまったので、(Facebookで募集した)少数の聴講者の前で語るイベントになりました。メディア関係者とエンジニア、双方がちょっと背伸びして読むような、読み応えのある記事になったかと思います。どうぞお楽しみください。
ゲスト紹介
藤村 厚夫
 スマートニュース株式会社 執行役員
スマートニュース株式会社 執行役員
2000年に技術者向けオンラインメディア「@IT」を立ち上げるべく、株式会社アットマーク・アイティを創業。2005年に合併を通じてアイティメディア株式会社の代表取締役会長として、2000年代をデジタルメディアの経営者として過ごす。2013年よりスマートニュース株式会社 執行役員/シニア・ヴァイス・プレジデントとして、「SmartNews(スマートニュース)」のメディア事業開発を担当。
古田 大輔
 BuzzFeed Japan 創刊編集長
BuzzFeed Japan 創刊編集長
朝日新聞社で社会部記者を経て、東南アジア特派員として現地の政治経済や社会を幅広く取材し、シンガポール支局長も務める。2013年の帰国後は、「朝日新聞デジタル」の編集者として、インフォグラフィックスや動画などを使ったコンテンツや、読者参加型のコンテンツ制作に携わった。また、朝日新聞社の新しいWeb媒体「withnews(ウィズニュース)」で新興メディアについて執筆するなどの経験と実績を経て、BuzzFeed Japan創刊編集長に就任。
辻 正浩
 株式会社so.la 代表取締役SEO
株式会社so.la 代表取締役SEO
2002年に広告業界に足を踏み入れる。テレビ番組・CM制作会社での制作ディレクターを皮切りに、制作会社、広告代理店などで勤務。その中で、特に取り組んだWeb制作・SEOについて技術を磨く。2007年より東京に拠点を移し、SEMを中心とした広告代理店でSEOコンサルタントに。2011年10月からフリーランスのSEO(Search Engine Optimizer)として活動の後、2013年7月に株式会社so.laを設立。代表取締役SEOとして成果を上げ続けるSEOを追求している。
Googleはコンテンツの品質を評価できていないのか?
白石 では本日最初の話題として、やはり昨年大変話題になったこちらの話(WELQ)から取り上げてみたいと思います。
(※筆者注: DeNAが運営する医療情報のキュレーションメディア「WELQ」が、クラウドソーシングなどを使って記事を安く大量に作り、その記事が検索結果で上位表示されていた件。医療系の情報にも関わらず信頼度が低い、記事の制作過程で多数の著作権侵害が認められるなど、多くの批判を受けて現在サイトは停止中)
ここにいる辻さんも、この件については関わられていましたよね。「死にたい」という検索キーワードでWELQの記事がトップに表示され、そこからキャリア診断サイトへの広告に誘導する…という流れを問題視したツイートが、すごく話題になっていました。

辻 はい、でもまあ、この件が一般的に大きく取り上げられたのは、BuzzFeedさんのニュースによるところがとても大きいです(と、古田さんを見ながら)。
古田 はい、ただ、恥ずかしながらぼくらはこの件について、最初はあまり重要性に気付けていなくて。 最初に世に広く知られるきっかけになったのは、9月に公開された朽木さんの記事だったと記憶しています。
藤村 この件で辻さんにお伺いしたいんですが、「Googleが品質の低い記事を見分けられない」という現状をどう考えられますか?
Googleは以前、単なるPageRankではなく、コンテンツの品質を見るようにアルゴリズムをアップデートした、と聞いています。そのおかげで、以前は「コンテンツファーム」と呼ばれる企業が低品質な記事を量産していたのを、海外では一掃できた。しかし日本ではその恩恵にあずかれていない、ということなのでしょうか?
辻 いえ、コンテンツファームの頃の「低品質」と、現在の「低品質」は全く違います。コンテンツファームによる低品質なコンテンツといえば、本当にひどかった。例えば「靴を手入れする方法」というタイトルの記事があるとしたら、「まず靴を履いてみましょう」から始まって、「そのあと靴に紐を通してみましょう」「紐を結んでみましょう」なんて内容だったりしたんです。

会場 (笑)
辻 こういう記事を1日数百記事ぶっこんでた、っていうのが2011年ごろ、パンダアップデート(Googleのアルゴリズム変更の名称)以前のWebでした。しかもこういう、ユーザーを満足させない記事っていうのは、広告がクリックされやすいんですね。そういう低品質なコンテンツに埋め込まれていると、広告が有用なものに見えやすい。だから、事業者が儲かってしまうんです。
ただ、こういうコンテンツはパンダアップデートにより弾かれるようになりました。そういう意味では、Webコンテンツの品質は全体的に向上しています。
藤村 なるほど。
WELQがなぜ検索結果上位を占めるようになったか?
辻 ここ数年のGoogleは、クリックやページ遷移などのユーザー行動データを機械学習させて、あきらかに検索アルゴリズムの中で用いています。このことを表立っていうとスパム業者の悪用が増えるので、昨年までは言わないようにしていたんですが。
白石 大丈夫ですか、これ記事にして(笑)。
辻 2017年になったしそろそろ言ってもいいかなと(笑)。最近はスパム耐性も非常に強くなりましたし。ユーザ行動を偽装するというスパムSEO会社もちらほらありましたが、今はGoogleの対策も進んで、スパムがビジネスとして成り立たなくなってきている。効かないのに金は取るっていう、詐欺業者は後を絶たないですけどね…
公式にはGoogleはユーザ行動のデータが直接ランキングに影響するということはずっと否定しています。でも、SEOの専門家の間ではほぼ常識になってきたくらいあきらかなことです。ユーザ行動の影響を私が怪しみだしたのは2013年末くらいで、それからずっとこの観点で調査や実験を続けていました。昔はほんのわずかな影響力でしたがどんどん強まりまして、去年あたりからは非常に大きな影響力になったと感じています。
以前はクローラーが収集してくるデータがランキング評価の95%くらいを占めていたと思いますが、今はもう60%くらいなんじゃないかと。そういう個人的な体感値です。

白石 なるほど、では、ユーザーの行動をアルゴリズムに反映していくことで、コンテンツの品質を評価しようとしているわけだ。
辻 はい。ただ、WELQはそのユーザー行動まで含めてSEOしていたので、検索上位に食い込むことができたわけです。例えば、WELQって長い記事が多かったですよね。読むのに5分くらいかかるような。そういう記事って、「長く読まれている」記事として、検索エンジンに対してプラスのシグナルが送られてしまうんです。
白石 確かに、内容が薄いけど長い記事って、目的の情報が出ることを期待して長く読んじゃいますよね…
辻 ただですね、これは(WELQの問題を糾弾した一人である)私だからこそ、覚悟を持って言えることだと思うんですが、WELQの記事は8割くらいは、そこまでひどい品質ではなかったと思うんです。もちろん、記事の制作過程で著作権を侵害していたとか、内容の信頼性に欠けていたなどの問題は別として。
白石 全くの嘘が書いてあったわけでもないし、役立つ情報も含まれていた気はしますね。別の問題はたくさんあったにせよ、単純にコンテンツだけ見るならば。
辻 だから、「WELQの記事が全て低品質だった」「それを見抜けなかったGoogleが悪い」と言うのは、少し極論だとは思います。ただWELQの記事は確かに、Googleの現在の(ユーザ行動を考慮する)アルゴリズムとは相性がよかった。だから、実際それほどリンクが多かったわけでもないのに、検索結果の上位に表示されていた、というのは事実だったと思います。
(編集部注: 2017/2/3、Googleは、日本語検索の品質向上に向けてという発表を行ったが、これはキュレーションメディアが検索結果上位に来ていたことが問題視されている世論への、Googleからの返答として広く受け止められている)
「Googleがユーザー行動を機械学習させる」って…?どうやって?
白石 ただ、先ほどからお話をお聞きしている中で、気になっていることがあります。HTML5 Experts.jpはテック系メディアだし、ちょっと技術的に突っ込んだ話も聞きたいな、と。
「クリックなどのユーザー行動をGoogleは検索に活用している」というお話ですが、そもそもどうやっているのでしょう?Googleの検索結果ページでリンクを踏むと、その先のページにリダイレクトしてしまうので、Google的にはその先のユーザー行動って追跡できないのではないでしょうか?
辻 そうですね、ちょっとお待ち下さい…(スマホを操作して)。こちらのページを見ていただいてもいいですか?
以前Google Nowと呼ばれていて、今「フィード」と呼ばれるようになっているサービスをご存知ですか?ユーザーのコンテキストに応じて、Googleが様々な情報を非常に高い精度で提案してくれる機能ですが、そこのヘルプページを見ると、「ウェブとアプリのアクティビティ」や「端末情報」といった情報を使用すると書いてあるんです。
白石 ほんとだ。そのヘルプページ、会場の皆さんにもお見せしたいですね。どうググれば出てくるかな?…あったあった。「端末やその他のGoogleサービスから取得した情報を使用します」って明確に書いてますね。
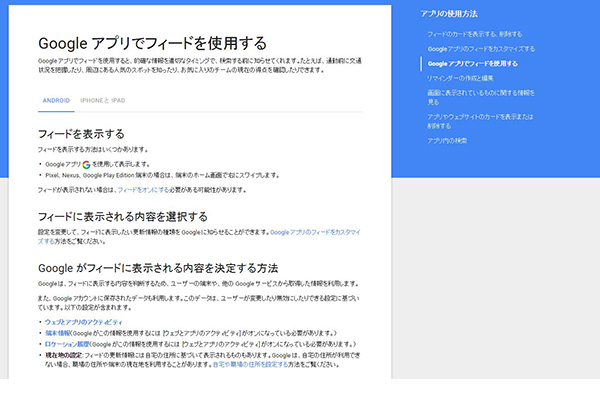 ▲ヘルプページ<Android 向け Google アプリアプリの使用方法ページ>
▲ヘルプページ<Android 向け Google アプリアプリの使用方法ページ>
藤村 Googleも、ここでこんなディープな議論が行われているとはよもや思わないだろうな(笑)。
辻 これはフィードの例ですので、パーソナライズに個人のログイン状態のページ閲覧データを使っているということですね。パーソナライズと全体公開という違いはありますが、Googleは検索以外のユーザー行動も幅広く利用してサービスに役立てていることは確かですし、それを検索に使われていない方がわたしは驚きます。そして、ヘルプページにも記載があるということは、活用は法的にも問題がないということでしょう。 ただ、繰り返しますが、こうしたデータを検索に利用しているという点については、Google自身は否定していますけどね。
「ユーザー行動×機械学習」ベースのコンテンツ評価アルゴリズムの悩ましさ
藤村 ちょっと、コンテンツの品質評価についての話に戻してもいいですか?
スマートニュースも、コンテンツの品質をアルゴリズムで評価するということにチャレンジしている企業なわけです。そうなると、「コンテンツの品質」というものを、科学的に定義付けなくてはならなくなるんですね。擬似的にか、本質的にかのアプローチの違いはおいても。そして、本来は(品質評価の)アルゴリズムについて、私たちは責任を持って広く語らなければならないと思っているんです。
しかしアルゴリズムについて語ると、アルゴリズムをハックしようとする動きが必ず出てくるので、そうもいかない。例えば、クリックやスクロール量と言ったユーザー行動をアルゴリズムが利用するようにしたら、クリックベイト(筆者注: タイトル詐欺のような手法)のように、そうしたユーザー行動を誘発しようとする動きも必ず出てくる。
そうなると、単にユーザー行動だけを単純に評価しても、コンテンツの品質を測るということにならなくなってくるんです。そのユーザー行動が、本当にコンテンツを好ましいと思って行われたものなのか。内容は、タイトルからユーザーが期待するものと一致していたのか。こういうことを知るには、ユーザー行動の裏にある、ユーザーの心理まで推測しないと。しかし、それはものすごく難しい。

辻 そうですね、ユーザー行動をベースにしたアルゴリズムには、そういう困難があるのは間違いありません。
例えば昔「ホロコースト」(ナチスによるユダヤ人大量虐殺)で検索を行うと、「ホロコーストはなかった」って内容の記事が検索結果の1番目に出てきていたんです。で、それに対する批判が高まったら、Googleは対策をして、そういう記事の評価を下げました。そういう対処がすぐに取れちゃうのもどうか、と思うんですけど(笑)。
でも、そういう記事の評価が下がったからといって、問題が解決したわけではありません。例え「ホロコーストはなかった」って記事が、検索結果の1番から2番に下ったとして、「ホロコーストはあった」ってタイトルと「ホロコーストはなかった」ってタイトルがあったら、「なかった」っていうほうをクリックしてしまいませんか?「ホロコーストがあった」なんて、当たり前のことで、何の目新しさもありませんから。
そして、「嘘ばっかりの記事だな」と思って、否定的な気持ちでそういう記事を読み始めたとしても、ツッコミどころを探すために長い時間読んでしまったりもする。そうすると、そのコンテンツにとってはプラスの評価になってしまうかもしれないのです。スキャンダラスな内容がより評価を受けがち、という問題があるわけですね。
白石 なるほど…根深い問題ですね。動機が異なるユーザー行動が、同じ方向に一緒くたに評価されてしまうわけだ。
「コンテンツの作り手」として、どう品質を担保すべきか?
古田 コンテンツの品質について、私たちがコンテンツの作り手としてどう考えているかもお話してもいいですか?
白石 もちろんです。どうぞ。
古田 私たちはオーディエンスの反応をすごく重視するので、ユーザー行動の測定はかなり真剣にやっています。例えば、記事タイトルのクリック率、記事の読了率、シェアの数とかですね。
さらにぼくらは、シェアされた内容も定性的に評価しています。肯定的な反応か、否定的な反応か。「このクソ記事」って罵倒してくる人は、どんな記事でも一定数いるんですけど(笑) 、その割合とかも含めて測っています。
そして、これでもまだ足りないと思っているんです。
例えば昨年、「ヒラリーがトランプを2013年に大統領に推薦した」というニュースが非常にシェアされました。しかしこれは嘘のニュースです(詳しくはBuzzFeedの記事を参照のこと)。この記事をシェアした人々は、大部分が記事に対して肯定的な反応をしているわけです。「これこそマスメディアが伝えない真実だ!」と。

つまり、シェアの内容を定性的に見るだけでも、記事の品質は測れない。だからぼくらは、最後は作り手自身がプロとしてチェックを行っています。
ぼくらは書き手であるライター・レポーターの上に、業界で10年以上の経験を持つエディターを置く…という体制を作っています。エディターは、ライターやレポーターの記事に対する品質をチェックする役割も担っています。そして最後にチェックするのは、編集長であるぼくです。
ただ最近は、さすがに(記事が多くて)全部は事前に見きれないので、公開された後に読んで、品質が高くなかったら指摘します。そうすれば、品質の低い記事が次また上がってくることはなくなり、コンテンツの質が一段と向上する。
先ほど、WELQの記事は8割くらいはまともに読めるものだった、というお話がありましたが、それって元から100点満点を目指していなかったと思うんです。最初から低品質の記事が混ざることも計算のうち、というかそれをよしとしていた。メディアのコンテンツプロバイダーをやる以上は、それではいけないと思う。たとえ難しくても、100点満点を目指す。間違いがあれば、素早く誠実に対応し、訂正する。それがメディアの責任です。
白石 素晴らしい。そこでお聞きしたいのですが、キュレーションメディアが記事を粗製乱造していたというのは、つまり記事の「コスパ」をとことんまで下げたいという論理の帰結だと思うのです。この「記事を作るというコスト」については、いかがお考えですか?
古田 そういう点で言うと、BuzzFeedってすごく「逆張り」している企業だと思うんですよね。記事を書くのは普通アウトソーシング、っていう業界において、記者を正社員雇用している。なぜそんなことをするかというと、理念を共有したいからです。結局、理念を共有するのに必要なのって話し合うこと、つまり「ミーティング」です。アウトソーシングしているのでは、理念を共有するために必要なミーティングの時間が持てません。
人件費は確かにコストです。ただ一方で、人材は財産という考え方もできます。「コスパ悪いから、成功できるわけない」って言われることもありますが、ライターが正当な対価をもらい、成長する場はメディア業界の将来のためにも必要です。成功したいですね。
フェイクニュースやプロパガンダサイトは今後もたくさん生まれる
白石 では、次の話題として、フェイクニュースとSNSについてお話をお聞きしたいと思います。
古田 フェイクニュースって言葉、バズってますよね。ただ、何がフェイクニュースで、何がフェイクニュースじゃないか、言葉の定義をしっかりしていかなくちゃいけないな、とは思います。アメリカのフェイクニュースって、意図的に作っているんです。最初から嘘の情報を拡散する目的で、ニュースに見せかけて作っている。日本だと、そこまでやってるってのはあんまり見かけないですね。低品質でもいいからバンバン作ってクリック稼ごう、というのが大半じゃないでしょうか。
藤村 そこに線引きするのは、なかなか難しいですよね。フェイクニュースには、悪意があるけども、一見してそれとわからないものも多い。
例えば批判のようなネガティブなコンテンツって、反対意見も出やすい。でも、ポジティブなコンテンツって反対が出にくく、逆に流布されやすいわけです。
こういう事実が、もはや白日の元に晒されてしまったわけです。実際、「alt-right」と呼ばれる人たちによる新興右派メディアが大量に立ち上がり、今回の大統領選に大きな影響力を及ぼしたと言われている。すごく安上がりに政治宣伝を行えるということを学んでしまった以上、今後こういうメディアは一斉に出てくると思います。
ただ、それに歯止めをかけたいと思っても、単に「右(寄りの思想)は許せない」なんていうのではいけません。それだと、左寄りのプロパガンダに対しては甘くなってしまうかもしれない。

古田 それでいうと、BuzzFeedって政治的な偏り全くないんですよね。
藤村 ホントですか(笑)?
古田 はい(笑)。そこは誓って。
以前、うちのCEOのJonah Perettiが、編集長のBen Smithとイベントで対談して、「リベラルなの?コンサバなの?」っていきなり聞いたんです。Benは「どっちでもないよ」って答えたんですが、Jonahは「その割にはリベラルなコンテンツ多いじゃん」と。そこでBenが言うには、LGBTQや移民などの、少数派の権利を守るための情報を発信することは、リベラルとかコンサバとかいう問題じゃなくて、公正の問題なんだと。「優しさ」と言ってもいいかもしれません。ぼくはこれに大変共感しました。
ぼくも、自分をリベラルとかコンサバとかそういう立場に置くつもりは全くなくて。むしろ、「なぜ世の中には自分のことをリベラルだとかコンサバだとか言えてしまう人間がこれほど多くいるのだろう?」というところに関心があるぐらいです。これ、ぼくの大学の卒論テーマだったんですけどね(笑)。
アドテクになってモラルハザードがすごい
白石 現在のWebメディアを支えている、広告というビジネスモデルについてもお聞きしたいです。2016年は、iOS Safariがコンテンツブロックを可能にしたことで、Web上で広告モデルが成り立たなくなるんじゃないか、なんて話題が大きく取り上げられました。また、先日Mediumが広告のビジネスモデルを批判して、大規模なリストラを行っていましたよね。
藤村 Mediumは、Bloggerの創業者であり、Twitterの共同創業者でもあったEvan Williamsが、5年くらい前に立ち上げたパブリッシング・プラットフォームです。広告を排除して、美しく、良質なコンテンツが生まれるクリーンな場所にしようと、お金を払って優良なコンテンツを誘致したりもしていた。
で、そのプラットフォームをどう収益化していくかにあたって、UXを阻害しないネイティブ広告あたりだろうと予想されていたし、実際50人くらい広告担当者が雇われてもいた。 しかし今年になって、「広告はワークしない。広告というビジネスモデルは壊れている」と言って、広告事業の部門を解雇したのです。じゃあ実際にどう収益化するのかと言ったら、まだそこは示されていないのですが。
白石 UXを重視するスタンスだと、広告モデルはできるだけ手を付けたくないところなんでしょうね。AppleがSafariにコンテンツブロッキングを可能にする際にも、WebのUXがよくないことを引き合いに出していました。
藤村 確かにWebの広告モデルにはUX上の問題も多い。あと、さらに言えば、アドテクになってモラルハザードがすごいんですよね。
白石 と、言いますと?
藤村 先ほど、フェイクニュースサイトが流行っている原因の一つに「安上がりにプロパガンダができる」と申し上げましたが、もう一つの大きな理由として、単純に「儲かるから」というのもあるわけです。フェイクニュースを発信すると、たくさんビューが稼げる。そこに広告を貼っておけばお金も入ってくる。政治宣伝にもなるし、ビジネスにもなるということで、たくさんのフェイクニュースサイトが生まれる。

古田 そう。アメリカ大統領選の時に、マケドニアの若者が140個くらいドメインを取得して、広告収入目的で、フェイクニュースサイトを立ち上げたらガッポガッポ儲かった、なんて話もあります。
辻 ドメインという話で言うと、WELQのあと、とある医療系メディアが450ドメインくらい取得して、現在どんどんランキングを上げているという状態です。医療系は広告がオイシイという事情もあるんですよね。そういう意味でも、広告モデルには問題が大きいですね。
藤村 これらの問題を別の側面から見ると、広告主がどこに自分の広告が表示されているのか知らないということです。自分たちの知らぬ間に、フェイクニュースサイトに広告が掲載されていて、運営者に資金を供給する形になってしまっている。そしてこの、アドテクの分野で最大手の企業が、やはりGoogleです。
白石 なるほど。しかしGoogle Adsenseは、例えばアダルトコンテンツを掲載したページには表示されないようチューニングされているとも聞きます。そういうフェイクニュースサイトに広告が配信されないよう、Googleも対策を取ろうとするんじゃないでしょうか。
藤村 そうですね。しかし、これまでも話に上がっていたように、どこからどこまでがフェイクニュースなのか、コンテンツの品質はどう測ればいいのか、そしてさらには特定の政治的スタンスを優遇する結果を招かないようにするといった、様々な問題があります。解決は容易ではないと思います。
辻 とはいえGoogleは、10年以上に渡ってクローラーの情報を元に検索アルゴリズムを作っていたのが、ここ数年で変わろうとしていて、今は大変革期なんですよね。抜本的な解決が2017年中に行われるとは考えにくいですが、確実に改善が見込まれる分野だとも思います。
Facebookがもたらす、「心地よさというバイアス」
藤村 Googleだけじゃなくて、(もう一つの巨大プラットフォームである)Facebookの話もしましょうか。
白石 はい、ぜひぜひ。フェイクニュースの拡散にはFacebookも一役買ってしまっていた、という話もありますし。
藤村 Facebookとしては、ユーザーにできるだけ心地良い場所を提供して、できるだけ長く利用してもらうというのがビジネスモデルの根幹です。ということは、できるだけ個々のユーザーが好む話題に寄せていってシェアを促し、ワイワイガヤガヤと「ハイパーアクティブ」な状態を作り出すのが望ましい。
例えば、シリアスな話題よりも「面白い」「きゃー可愛い!」と言った話題の方がシェアされやすいのなら、そういう情報ばかりをユーザーに提供する。以前、黒人の青年が殺害されて全米で大規模な抗議デモが起きたときも、ある社会学者が自分のニュースフィードにはそういう情報がほとんど表示されなかった、なんて話もあります。

白石 確かに。Facebookのニュースフィードって、心地いいけど、ちょっと現実社会から切り離された感覚あります。
藤村 もちろん、Facebookがそれを念頭に置いてサービスを設計しているかどうかはわかりませんが、そういう方向にチューニングしていくモチベーションがあるのは間違いないと思います。Facebookとしては、「楽しい話題のほうが儲かる」ということが起きている可能性がある。
この話のキモは、そういうFacebookのビジネスモデルとサービス設計が、ユーザーにとって意図せざるバイアスをもたらしている可能性があるということです。そして、ユーザーはそのことにまず気付けない。
白石 気付かないうちにバイアスのかかった情報にばかり接している…という状況に陥るわけですね。フィルターバブルと言われている現象ですね。
こうしたインターネットメディアの問題といかに戦うか?
聴講者 ちょっと質問してもよろしいでしょうか?
白石 はい、どうぞ。
聴講者 バイアスについてのお話がありましたが、ユーザーがそれを望んでいる、楽しい話題を望んでいるのであれば、止めることはできないのではないでしょうか? シリアスな話題を提供したとして、1人にも読んでもらえないとしたら、それはサステナブル(ビジネスとして持続可能)ではないのではないですか?
そして、「楽しいところにみんな集まる」というのが当たり前だと思うので、たとえそれが嘘のニュースであっても、楽しければ喜ばれてしまうと思うのです。これって、止めようと思っても無理がある、よくてイタチごっこになってしまうような気がするのですが、いかがでしょう?
あと、本日のパネリストの皆さんはある意味コンテンツの提供者側ですが、読者としてはどうしたらいいのでしょうか?

古田 ぼくの立場からお答えしますと、まず「読まれなかったらサステナブルじゃない」というのはその通りです。ただ、シリアスなコンテンツがシェアされないかというと、そんなことはありません。BuzzFeedを1年やってきましたが、非常にシリアスでボリュームのあるコンテンツが、たくさんシェアされるのを見てきました。
そして嘘ニュースについては、ぼくらは「それ嘘じゃん」と指摘する作業をやってみればいい、と思っています。
政治的な記事だけではありません。例えば以前、ネットで「感動する話」として話題になっていた記事が事実かどうかチェックしたら、全然違ったこともあります。そういうコンテンツはどんどん出てくるので、「イタチごっこか」と言われればまさにその通りです。ぼくらはそのイタチごっこを「やりましょう」というスタンスです(笑)。
あと、オーディエンス(読者)の皆さんが今の時代、嘘のニュースとどう向き合えばいいかという話についてですが、そもそも今まで嘘のニュースってありませんでしたか? そんなことはない。怪しい雑誌とか新聞とか、そういうのはたくさんあった。今の時代はそれを指摘できるようになっているわけで、ある意味紙の時代より良くなったと言えるかもしれないのです。
人気ライターのヨッピーさんが、サイバーエージェントのSpotlightというメディアを批判する記事を書いた件で取材したのですが、彼が言うには、「読者は神様だ」「悪質な記事というのは神への冒涜だ」だと。オーディエンスに高いリテラシーを要求する世の中は間違っている、Webメディア自体がもっと良いものになっていかなくてはならないと。ぼくもヨッピーさんに同感ですね。
辻 その問題は、検索という観点からいうと、サイト単位の評価をもっと読者も運営者も意識すれば解決に近づく話なのかな、と思っています。 検索エンジンはページ単位ではなくサイト単位でも評価をしていますし、その軸での評価の精度はどんどん高まると思っています。
白石 なるほど、情報源ごとに「信頼度」のようなものを持たせているわけですね。
辻 はい。なので読者側がもっとサイト単位で好き嫌いを意識して使ったりシェアしたりするようしていれば、メディア側は読者の「媒体愛」を育てる、っていうモチベーションが生まれるんじゃないかなと思いますし、それがサステナブルにもつながると思っています。
ただ、SmartNewsとかで読んでると、「どこの媒体の記事か」ってあんまり意識せずに読んでしまいますけどね…。あ、、、SmartNewsのアプリは、いつも便利に使わせていただいています!(笑)

彼らが考える、Webメディアの未来
白石 では、そろそろこの座談会も終わりにしたいと思いますが、最後のトピックとして、Webメディアの未来について語っていただければと思います。直近ではなくて2020年とか、少しだけ想像力を働かせていただきつつ、少し未来を想像してお話いただけますでしょうか?
古田 2020年といっても、みんなが使っているデバイスはスマホで変わらないと思うんですよね。薄いとか曲がるとか、そういう進化はあると思いますが、少なくとも手元で、これくらいのスクリーンサイズで、っていうのは変わらないと思う。
2020年には、VRでオリンピックを見るっていうのがすごく流行るとは思うんですけど、ぼくはVRって「フランス料理」だと思うんですよね。毎日食べたいか?と言われるとそんなことはない。だから、毎日食べる定食としてのメディアの表現技法というのは、今とそれほど変わらないんじゃないかと思います。
そんな中で2020年には、インターネットメディアの質を向上させるための業界団体とかが立ち上がってるんじゃないかな、と思いますね。「インターネットメディア」といっても、既存のメディアを排除するわけじゃない。今Webサイトを持っていないメディアなんて皆無なので、むしろみんながインターネットメディアなわけです。
そういう団体を通じて、コンテンツの品質を担保しつつ、日本から世界に情報を発信していく。2020年には、そういう状態になっていればいいな、と思います。

辻 2020年には、検索アルゴリズムが今よりさらに改善されて、現在の問題というのはだいぶ解決しているだろうと思います。今の不具合というのは、クローラー以外のデータ(ユーザー行動など)を使い始めてまだ2,3年と、日が浅いからだと思っています。
他には、半分期待と希望も込めつつ、日本のメディアが海外に出ているといいな、と思いますね。今は、海外での存在感がゼロに等しいので。
白石 なるほど。海外に出るとなるとお金も必要ですよね。Webメディア、もっと稼がないと。
辻 はい、でも、(検索)アルゴリズム的には、2,3年前に比べると出やすくなってるんですよ。それに、日本のWebメディアが世界に出るとなると、ソーシャルだと厳しいじゃないですか(国や言語のバリアが高い)。なので、検索をうまく使って世界に出ていくべきだし、そうなればいいと思っています。
藤村 ちょっと、先ほどの参加者の方からの質問を受けて、って感じでもあるんですけど。「世界は多様性に満ちている」ということ、そしてそれを隠さないようにしていきたいと思っています。
SmartNewsのようなニュースアグリゲーターもそうあるべき。栄養と同じですね。好きなものばかり食べていたら栄養が偏るよ、と。バランス良く栄養を取りましょう、と。 2020年という時点においても、そういう課題を追い続けている気がします。
その上で、読者はもっと自由になる。コンテンツを消費する方法も多様化して、ポケットから取り出したデバイスで気軽に見たり、それをゴージャスな大画面で見ることもできる。そういうふうな世界で、多様な視点を提供できるように頑張っているのかな、と思います。
白石 皆様、本日はどうもありがとうございました。大変勉強になりました。

