「漫画家の先生をゲストに迎えた対談イベントで、“マンガ”をフィーチャーしたエンターテインメントを最新のWeb技術で作れないだろうか?」そんな思いから生まれた「マンガテレビ」。映像をリアルタイムで“マンガ化”するだけでなく、イベントをもり上げる各種機能が盛りだくさん。今回は、そのアーキテクチャを紹介します。
マンガテレビの紹介
「マンガテレビ」は最新のWeb技術をふんだんに活用し、イベント映像を“リアルタイムでマンガ化”するエンターテイメントツール。俗にいう「技術の無駄遣い」Webアプリケーションです。我らが、HTML5 Experts.jpの編集長「白石俊平」氏が開催している「(白石俊平と)カッコいいやつら」のイベント用ツールとして開発しました。
「マンガテレビ」を説明するのに言葉は不要。とにかく、サイトにアクセスしてみてください。ただし、Chromeでしか動作しません(後述のWeb Speech API利用のため)ので、その点ご注意ください。
なお、初回アクセス時は、下図のようにカメラとマイクへのアクセスを確認するダイアログが画面上部に表示されますので、「許可」をクリックしてください。
![]()
![]()
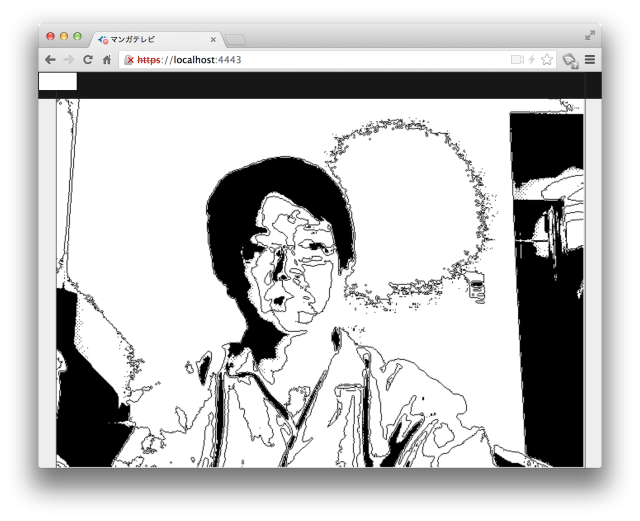
かの有名アプリ「漫画カメラ」を最大限に「リスペクト」したことは一目瞭然です。なお、「マンガ化」のアルゴリズムはこちらのslideshare(スライド9)を参考にさせていただきました。
しかし、そのままリスペクトするだけではなく、Webならではの機能をふんだんに盛り込みました。
盛り込んだ機能は大きく二つ。一つ目は「みんなで『かっこいいね!!』」機能です。これにより視聴者参加型の「マンガテレビ」を実現しました。
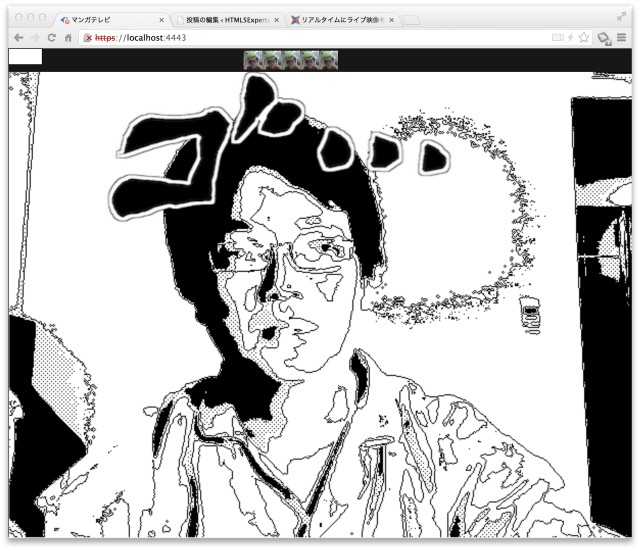
Webの特徴は、みんなが簡単に繋がれること。そこで、白石さん謹製の「かっこいいねボタン」と連携し、様々なエフェクトがかかるようにしました。「ボタン」を3回連打すると「ざわ・・」、5回連打すると「ゴ・・・」が画面を横切るという仕掛け。イベント参加者が「ちょっと、かっこいいね!」と連打すれば「ざわざわざわ・・」が、「すごい!!かっこいいね!!」と連打すると「ゴゴゴゴゴゴ・・・」と文字が横切っていきます。
もう一つは、「自動吹き出し機能」。最新Webの目玉機能の一つ “Web Speech API” を使い自動認識した音声を、吹き出しとして表示する機能です。
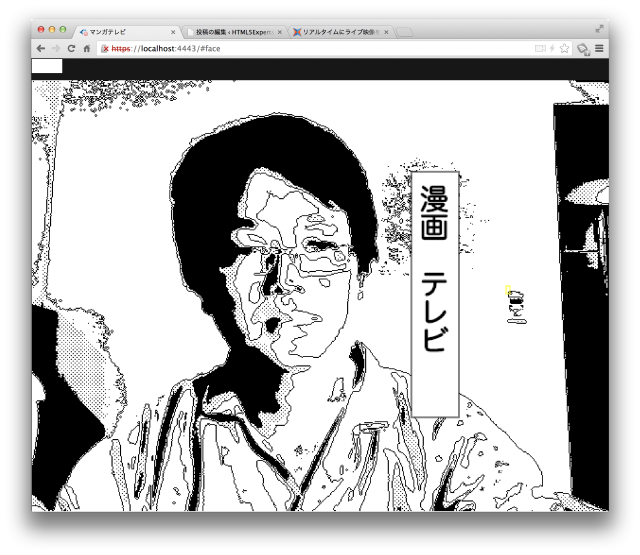
音声認識には誤認識がお約束ですが、その誤りっぷりが相まって、さらにエンターテイメント性を引き立ててくれています。なお、吹き出しの表示位置を調整するために、顔検出機能を利用しています。技術の無駄遣いっぷりは半端ではありません。
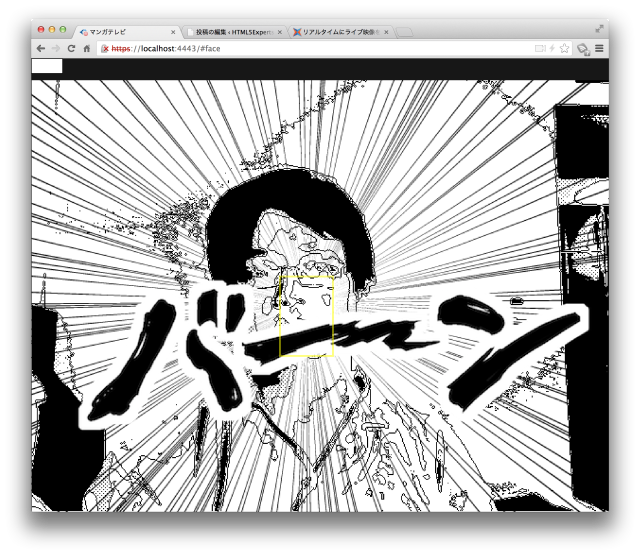
また、”WebSpeech API”による音声認識機能を応用し、音声コマンド機能も実装しました。例えば「バーン」と話すと、画面に集中線と「バーン」が表示されます。イベントの盛り上がりに欠かせない機能です。
なお、開発メンバーは、筆者を含め HTML5Experts.jp 編集部メンバー4名で開発しました。
マンガテレビ実装のポイント
この「マンガテレビ」の実装のポイントを紹介します。本稿では、以下の4点について紹介します。
- WebRTC と HTML5 canvas による映像のリアルタイムマンガ化
- WebSpeech API による音声認識
- headtrackr.js による顔検出
- WebSocket によるインタラクティブ機能
getUserMediaとHTML5 canvasによる映像のリアルタイムマンガ化
最初に紹介するのは「マンガテレビ」の基本機能。リアルタイムで映像を「マンガ」にする機能の実装方法の紹介です。
ステップは以下のようになります。
- WebRTC の getUserMedia() により、カメラから映像を取得する。
- HTML5 canvasのgetImageData() により、映像から画像データを取り出す。
- 画像データにフィルター処理を行い、マンガ化する。
- requestAnimationFrame() により、画像変換処理を繰り返す。
WebRTC の getUserMedia() により、カメラから映像を取得する。
まず、カメラから映像を取得します。これを行うためWebRTCのgetUserMedia()を使っています。(前述のとおり、Chromeを前提としているため、接頭辞 webkit を記述しています)
$v_ = $("video");
// カメラからのストリーム映像を取得し、videoノードのsrc属性にURL指定する navigator.webkitGetUserMedia({video: true, audio: false}, function(stream){ var url = window.webkitURL.createObjectURL(stream); $v_[0].src = url; $v_[0].play(); });
取得するのは映像のみのため、第一引数のaudioプロパティはfalseとしました。第二引数は取得成功時のコールバック関数で、カメラから取得した映像はインスタンスstreamに返されます。ここで、「マンガ化」の変換処理を行うためには、一旦streamをURLに変換し、videoノードにsrc属性として指定する必要があるため、 createObjectURL()を用いています。また、video ノードは、play()をコールしないと映像再生が開始しないため、このタイミングで呼んでいます。
HTML5 canvasのgetImageData() により、映像から画像データを取り出す。
マンガ化する画像変換処理を行うためには、映像から画像のピクセルデータを取得しなければなりません。このため一コマづつcanvasに画像として書きだし、getImageData()により、取得します。
var canvas = $("canvas")[0]
, ctx_ = canvas.getContext('2d');
// 映像の一コマを一旦canvasに画像として書き出す ctx_.drawImage($("video")[0], 0, 0)
// canvasから画像のピクセルデータを取得する var imgData = ctx_.getImageData(0, 0, 640, 480)
画像データにフィルター処理を行い、マンガ化する。
取得した画像データに対してフィルター処理を行いマンガ化します。アルゴリズムは以下の通りです。
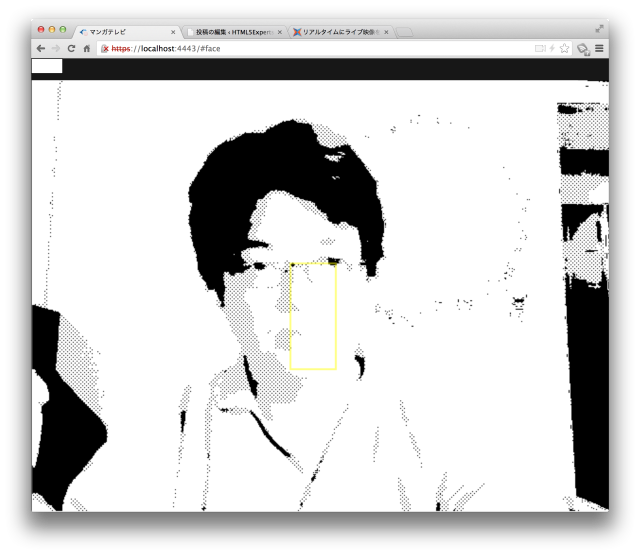
- 画像を黒・スクリーントーン・白の3階調化する。
- エッジ抽出を行い、階調画像に縁取りを行う。
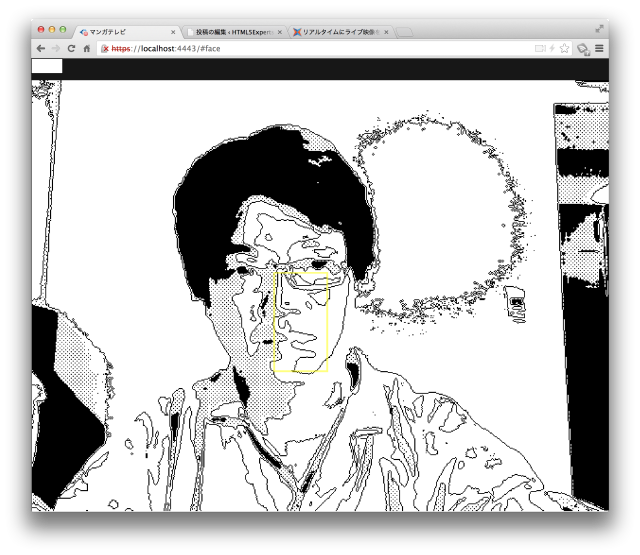
(階調処理やエッジ抽出の具体やコードについては次回の記事で紹介します)
上記フィルター処理を行ったデータをcanvasに描画し、「マンガ化」された画像が表示されます。
// 「マンガ化」フィルター処理後のデータを、canvasに書き出す。
ctx_.putImageData(toon, 0, 0)
requestAnimationFrame() により、画像変換処理を繰り返す。
上記操作を16msec毎にループ処理することで、60fpsで「マンガ化」された映像が表示されます(パラパラ漫画の要領です)。このような処理を行う際、これまでだと
// doToon()は、映像の一コマを画像変換する関数
setInterval(doToon, 16);
と、setInterval()を用いるのが普通でした。しかしながら、このコードでは、doToon()の処理に16msec以上かかった場合、処理がスタックしていく問題が生じます。ここで、requestAnimationFrame() を用いると、doToon の処理時間に応じ、画像フィルター処理が繰り返し実行され、適切なフレームレートでマンガ化された映像が表示されます。
requestAnimationFrame(doToon)
WebSpeech API による音声認識
二番目に紹介するのは、音声認識機能です。認識した音声を吹き出しに自動表示したり、音声コマンドを使ったりするためにこの機能を利用しています。
音声認識を実現するために、Chrome で試験実装されている WebSpeech API を利用しました。ちなみに、このWebSpeech APIはW3Cで正式なドラフトも出ていない実験的なAPIです。音声認識が簡単にできてしまうなんて、ほんとブラウザの進化は留まるところを知りません。今後、本格的な仕様化や実装が進んでいくことでしょう。楽しみですね。
インスタンス生成後、start()メソッドをコールすると、音声認識が始まります。
var rec = new webkitSpeechRecognition();
rec.continuous = true; // 音声認識を継続する rec.interimResults = true; // 認識処理中の候補も返す rec.lang = 'ja-JP'; // 認識モードを日本語にする
rec.start(); // 音声認識を開始
音声が認識されると、’result’ イベントが発生します。認識結果は、SpeechRecognitionEventオブジェクトとして返されます。
rec.onresult = function(ev) {
for(var i = ev.resultIndex, l = ev.results.length; i < l; i++) {
if(ev.results[i].isFinal) {
// 音声認識が完了した
var res = ev.results[i][0].transcript; // 音声認識結果
} else {
// 音声認識途中
var res = ev.results[i][0].transcript; // 音声認識中の途中結果
}
}
}
「マンガテレビ」では、認識結果の値をチェックし「バーン」や「ドーン」などの場合は、音声コマンドとして認識し、映像エフェクトを実施。それ以外の場合は、吹き出しに表示するといった処理を行っています。
なお、イベント中講演者が話し続けているようなケースだと、ずっと音声認識中となり、認識が完了しないケースが頻繁に発生します。これを避けるため
// 認識結果の文字列長が15文字を超えたら、認識を再起動する。
if(res.length > 15) {
rec.stop();
rec.start();
}
のように、認識結果が15文字を超えた時点で音声認識を再起動する処理を入れています。
なお、再起動の際に、サイトのプロトコルスキーマがhttpsでない場合、毎回音声認識の許可を求めるダイアログが表示されてしまいます。注意してください。
headtrackr.js による顔検出
次に紹介するのは、顔検出機能です。音声を表示する吹き出しや、音声コマンドで集中線を出す際の位置を決めるために、この機能を利用しています。
JavaScript で顔検出を行うライブラリーとして face.js が有名ですが、検出スピードに難があるため、より高速に動作する headtrackr.js を用いました。
headtrackr.jsは、最初に顔検出を行うまでは低速ですが、一旦検出が完了すると、それ以降は検出した顔の周辺のみを検出対象とするため、face.jsに比べ格段に高速動作します。もちろんハードウェアに依存しますが、筆者の Mac Book Pro では、概ね30fps(frame per second : 1 秒辺りのフレーム数)が得られました。ただし、検出できる顔は一つのみとなりますので、その点は注意してください。
Tracker オブジェクトのインスタンスを生成した後、検出対象のビデオ要素と、検出処理に用いるcanvas要素を指定し、start()メソッドを呼ぶと顔検出処理が始まります。
var tracker = new headtrackr.Tracker({ui: false}); // uiをfalseにしないと、検出状態を示すテキストが表示される。
tracker.init($("video")[0], $("canvas")[0]); // 対象ビデオ要素と、検出処理用canvas要素を指定する。
tracker.start(); // 顔検出を開始する。
顔が検出されると、’facetrackingEvent’ イベントが発生します。認識結果は、コールバック関数にfacetrackingEventオブジェクトとして返されます。
document.addEventListener("facetrackingEvent", function(ev){
// ev.x, ev.y -> 顔の中心座標
// ev.width, ev.height -> 顔の幅と高さ
}, false);
これら顔の検出位置情報から、吹き出しの表示位置を決めています。
WebSocket によるインタラクティブ機能
最後に紹介するのは、インタラクティブ機能です。イベント参加者が「かっこいいねボタン」を連打すると、それがWebSocketで「マンガテレビ」に送られ、連打の数に応じて「ざわ・・」とか「ゴ・・・」などの文字が横断するエフェクトが動きます。参加者も一体になって盛り上がれるインタラクティブ機能です。この連打の数を「マンガテレビ」に送るために、HTML5の双方向通信機能WebSocketを使いました。なお、『マンガテレビ」では、socket.ioを用いているため、WebSocket が利用できない環境では自動的にHTTPポーリングにフォールバックします。
「マンガテレビ」では、socket.ioを更にラップし、メッセージ受信をsubscriberモデルとしたZapper オブジェクト(白石さん謹製)を用いています。
Zapperオブジェクトのインスタンスを生成し、connect()メソッドでサーバーへ接続。その後、’zap’メッセージに subscribe()すると、「かっこいいねボタン」の連打データを受信することができるようになります。受信データのcountプロパティに連打回数が入っているため、その値に応じて「ゴ・・・」や「ざわ・・」といったエフェクトをかけています。
// 接続先サーバーを指定してインスタンスを生成
var zapper = new Zapper({
serverUrl: 'http://somewhere'
});
zapper.connect(function() { var event = zapper.event();
event.subscribe('zap', function(zap){ // zap.count に連打回数が格納されている }); });
次回はパフォーマンスチューニング
今回の記事では、筆者らが最新Web技術を駆使してイベント用に開発した「マンガテレビ」について、そのアーキテクチャを紹介しました。HTML5 の進化によりブラウザの世界観がさらに広がっていくことを感じて頂ければ幸いです。
さて、「マンガテレビ」では、本稿で紹介した各種機能以外に、もう一つ大切な点が。それは「高速動作する」ことです。映像のマンガ化処理に時間がかかると、「マンガテレビ」はカクカク動いてしまい、イベントが興冷めしてしまいますからね。次回は、「マンガ化処理」を高速に行うためのパフォーマンスチューニング・ポイントについて紹介します。
