Webブラウザの上で動作するアプリを書くための言語、といえば何が想起されるでしょうか。Flash、Sliverlight、Java、さまざまな言語が利用されてきましたが、やはり今のメインストリームはJavaScriptでしょう。
JavaScriptはさまざまな言語の特徴を併せ持つ動的言語で、Web技術の発展とAPIの整備の結果、Virtual Reality(VR)や画像認識、DAW(Desktop Audio Workstation)といった、少し前まではネイティブでの実装しかありえなかった種類のアプリケーションもWebブラウザをランタイムとするJavaScripで実装されるようになってきました。
そのようなアプリの代表例がゲームでしょう。少し前までのブラウザゲームといえば、リロードを繰り返すタイプのゲームか、Flashゲーム、パズルなどの簡単なものが大半を占めていたように思います。Canvasを利用して実装されたスーパマリオやNESエミュレータなどもありましたが、いずれも実験的なものであり、また20年以上前のハードウェアで快適に動くゲームだったことを考えると、CPU時間を大量に消費する「重厚」なものではありませんでした。
しかし最近は重厚なゲームの開発も行われ始めています。この嚆矢はBananaBreadでしょう。これはMozillaのエンジニアチームが開発した複数同時対戦可能なFPS(First Person Shooting)です。このようなゲームの実現が可能になったのは、WebGL、Web Workers、Web Audio API、Gamepad API、IndexedDBなどに代表されるAPIの充実もありますが、既存のJavaScriptエンジンではなしえなかった高速の演算を可能にする、低水準言語の整備のおかげでもあります。
この連載は4回にわたって、Webブラウザ上で動作する低水準言語であるasm.jsと、(いまのところ)そのバイナリフォーマットであるWebAssemblyについて、その設計と仕様、そして開発環境を紹介します。
低水準言語asm.js
asm.jsはMozillaが研究開発したJavaScriptのサブセットで、2013年に発表されました。現在はFirefoxとGoogle Chromeによって実装が行われ、EdgeやSafariも対応を表明しています。その特徴はなんといっても動作の高速さです。次のグラフはasm.js発表時に公開されたベンチマークの結果で、棒グラフが短ければ短いほど、処理が高速であることを意味しています。このグラフによると、ベンチマークの種類にも依存しますが、概ねCやC++によるネイティブ実装の半分程度のスピードで動作していることがわかります。
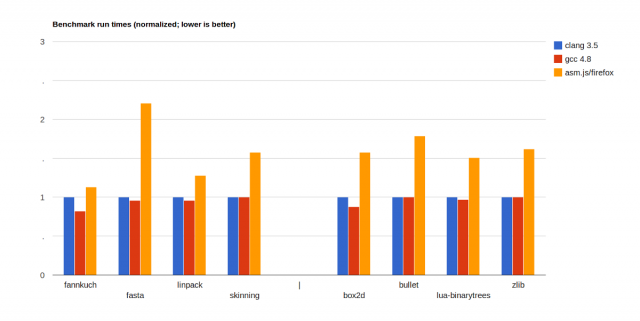 https://kripken.github.io/mloc_emscripten_talk/cppcon.html#/24より引用
https://kripken.github.io/mloc_emscripten_talk/cppcon.html#/24より引用
このような高速に動作を可能にしているのは、事前コンパイルと呼ばれる技術です。AOT(Ahead of Time)とも呼ばれるこの技術を利用すると、プログラムはその実行直前にコンパイルが行われ、ネイティブコードへと変換されます。ブラウザは内蔵するコンパイラでasm.jsで書かれたコードをネイティブコードに変換し、ネイティブコードを実行することで、この高速性能を実現しているのです。
事前コンパイルを可能とするために、asm.jsで書かれたプログラムは以下にあげる特徴を持っています。
- 変数や式、関数の型が静的解析可能である
- 数値計算に特化している
- 作成や属性の参照、メソッド呼出といったオブジェクトに関する操作ができない
- 利用できるコレクション型はTyped Arrayのみである
一般のJavaScriptやAngular、RxJSといったモダンなフレームワークの提供するDSL(Domain Specific Language)に 慣れた身からすれば、機能が制限され、「低水準な」印象が拭えません。2013年にもなって、なぜ、このような制約の強い言語が開発されたのでしょうか。もちろんJavaScript発展の文脈に基づく、実用上の要求があるためです。それを理解するに、まずJavaScriptの動作について簡単に(かつ大雑把に)振り返ることとしましょう。
JavaScriptが動く仕組み
プログラミング言語は「コンパイラ型」と「インタプリタ型」の2つに分けることができます。C言語やC++は前者の典型で、 後者の典型はPerlやRuby、Pythonでしょう。JavaScriptも後者に分けられます。インタプリタ型の特徴は、あるプログラムの動作に「インタプリタ」と呼ばれる別のプログラムが必要である点です。SpiderMonkey(Firefox)、Chakra(Edge)、V8(Chrome / Node.js)はJavaScript向けのインタプリタとして有名でしょう。
インタプリタは、文字列を解釈してプログラムとしての文法的構造を取得します。この過程を字句解析・構文解析と呼び、 結果得られた文法的な構造のことを抽象構文木(AST: Abstract Sytactic Tree)と呼びます。例えばa=1+2*3; のASTは次のようになります。
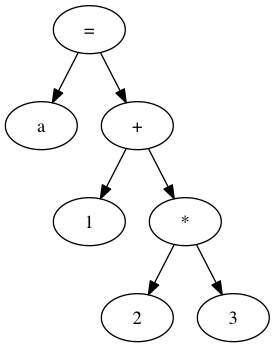
素朴なインタプリタは、この抽象構文木を枝の方から実行していきます。先ほどの例だと、まず2 * 3の計算を行い、 その結果である6で2 * 3に相当する部分木を置き換えます。その後1 + 6を計算し、最後にa = 6を計算します。この場合では、*や+、=といった演算子や標準ライブラリ中の関数などは、インタプリタ中の関数として実装され、それらをASTを解釈する巨大なswitch文の中から呼び出してプログラムは実行されます。そしてこの巨大なswitch文は、プログラムの評価が終わるまで繰り返し実行されます。
仮想マシンとバイトコード
このようなインタプリタはシンプルで理解しやすいのですが、変数のスコープや返り値の受け渡しの実現が困難になりがちです。そこで多くのインタプリタはASTをバイトコードに変換して実行します。バイトコードは単なるASTのバイナリ表現ではなく、インタプリタによって実装された仮想的なハードウェア(仮想マシン)を動かすマシンコード、つまり仮想的なネイティブコードとなっています。例えば(a,b,c)=>a+b*cという関数は、SpiderMonkeyによって次のようなバイトコードの列に変換されます。
|
1 2 3 4 5 6 7 |
getarg 0 getarg 1 getarg 2 mul add return retrval |
getargやmul、addなどはSpiderMonkeyの実装している仮想マシンの持つ命令です。仮想マシンには計算に使う値をスタックに保存するスタックマシンと、レジスタに配置するレジスタマシンとがありますが、SpiderMonkeyはスタックマシンを採用しており、変数への代入や、実引数の参照はスタックに対する操作として実現されています。
なおSpiderMonkeyの提供するバイトコードはこちらのサイトで一覧できます。
バイトコードに変わったとはいえ、実行のモデルは変わりません。バイトコードを1つずつとってきては、バイトコードを解釈する巨大なswitch文を通じて、各命令を実装する関数が呼ばれます。これがプログラムの実行が終了するまで繰り返されます。
型情報の不足
どうせネイティブコードを出力するなら、仮想マシンのネイティブコードではなく、実マシンのネイティブコードを出力すればいいのに。そう思われるのも当然ですが、出力しない、もしくはできないのにも理由があります。それらの中で大きなものの1つが、型情報の不足です。
|
1 2 3 4 5 6 7 |
function wrap(value){ return {value: value}; } var b1 = wrap(1); var b2 = wrap(2); var result = b1.value + b2.value; |
resultにはどういう種類のデータが入るでしょうか?数値とすぐわかる方も多いとは思います。ではなぜ数値だとわかったのでしょうか?頭の中で上記のプログラムを実行した結果、b1.valueとb2.valueの値が両方とも数値であることがわかり、 数値同士の加算は数値になることから、resultには数値が代入されると結論づけたのではないでしょうか。
では、このwrapの返り値のvalue属性には常に数値が代入されているでしょうか?wrapの引数は数値でなければならない、とはどこにも書いてありません。そのため、次のような呼び出しも可能です。
|
1 2 3 4 |
var b3 = wrap("abcd"); var b4 = wrap({id: 1234}); var b5 = wrap(null); var b6 = wrap(undefined); |
b3,b4,5,b6それぞれのvalue属性の型も、string,object,null,undefinedと異なる型になっています。 このようにJavaScriptのプログラムは実行するまで変数や演算結果の型がわからないことが多々あります。 これはプログラムの中に型の情報が含まれていないためです。 もし型情報が含まれていれば、実行しなくても変数や演算の結果の型を決められます。 型付けの強い言語の代表例であるRustを使って同様のプログラムを記述すると、次のようになります:
|
1 2 3 4 5 6 7 8 9 10 |
struct Box<T>{value: T} fn wrap<T>(value:T) -> Box<T>{ Box{value: value} } fn main() { let b1 = wrap(1); let b2 = wrap(2); let result = b1.value + b2.value; println!("result = {}", result); } |
このプログラムでは実行しなくても、resultの型はintであることがわかります。resultの宣言からは、型宣言を省略してあります。それでもRustの処理系は他の情報から型を決定して型を決めています。それはBoxとwrapの宣言についている型情報、そしてwrapを呼び出した際の引数から、b1.valueとb2.valueの型が決定できるためです。
さて型がわからないことが、ネイティブコードの出力にどのような影響を与えるのでしょうか。それは端的にいえば、出力するネイティブコードが冗長になるということです。例えばIntelのCPUの場合、加算だけでも20種類以上の命令があります。 これはデータ型と、データの保存場所によって使用する命令が異なるからです。データ型が適切に決定できているなら、使用する命令を1つに絞ることができます。
しかしデータ型を適切に決定できない場合、その可能性を1つずつチェックし、そのチェックした結果に合わせて使用する命令を決めるといったようなコードを出力せざるをえません。その結果コード全体は冗長になり、スピードもあまりでなくなってしまいます。ネイティブコードの出力にも時間がかかるため、その時間に見合った効果が得にくくなってしまいます。
JITコンパイル
ネイティブコードを出力したいが、ソースコードには型に関する情報がない。この状況を打破するために利用されている技術がJIT(Just in Time)コンパイルです。これはJavaScriptをいきなり高速に動かすためのネイティブコードに変換せず、しばらくインタプリタなどで動作させます。変数に代入される値を観察して、その型に関する統計情報を集めます。
この統計情報と、1つの変数には同じ種類のデータが代入される傾向にある、というヒューリスティックを利用してその変数の型を推定していきます。推定がある程度できた時点で、該当するコードからネイティブコードを出力します。このようにプログラムを動かしながら、必要に応じてネイティブコードへと出力するのがJITです。
SpiderMonkeyではJITは2段階に分かれています。まずはnullチェックなどを含んだ冗長なコードを出力するベースラインJIT を行います。その状態でしばらく動作させ、型情報の統計を取得します。ある程度の型情報が集まったところで、その情報を元により効率の良いコンパイルを行います。
図中のIon compileがそれです。
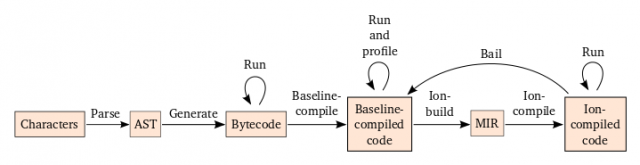 asm.js AOT compilation and startup performanceより引用
asm.js AOT compilation and startup performanceより引用
型情報が集まったかどうかは実行回数によって決まっているようです。コードをざっと眺めた限り、10回程度繰り返し実行されるかどうかが、コンパイルを行うかどうかの判断の目安になっているようです。
上図のように、コンパイルされたコードは常に維持されるわけではありません。ときにはbail、つまりコンパイル結果を捨てて、もう一度型の推定からやり直します。これはJavaScriptの関数呼び出しに型による制約がかけられず、推定がヒューリスティックによるもののため、仕方がないことです。例えば、次のような呼び出しが行われた場合twiceのコンパイル結果は捨てられてしまいます。
|
1 2 3 4 5 |
function twice(a){ return a + a; } var array = [0, 1, 2, 3, ... , 100000].map(twice); var str = twice("こんにちは"); |
map関数からの呼び出しによってtwiceは10000回実行されます。この途中で(正確には、行われるかどうかは処理系に依存するのですが)、twiceはnumberを引数にとり、numberを返す関数としてJITコンパイルされます。しかし次の行の引数に文字列が与えられた呼び出しによって、その結果は捨てられてしまいます。捨てないとこの処理が行えないためです。
TypeScriptのような型制約があればこのようなことが起きないのですが、残念ながらJavaScriptにはそれがありません。 そのため時には時間をかけて行ったコンパイル結果を捨て、低速に動くことを余儀なくされてしまいます。
まとめ
JITを利用することで、よく利用されるコードを高速に動作させられるようになりました。 それでも次のような問題が残っています。
- よく使うコードしかネイティブコードにならない
- 高速に動作するようになるまでにはリードタイムが必要
- 型の推定には失敗することがある
重厚なゲームのようなアプリケーションの場合、2や3の問題は致命的なものとなりえます。
FPS(First Person Shooting)で対戦している場合を想像してみてください。対戦の最初はコンパイルがすんでいないため、ゲームはもっさりと動作しています。これではゲームになりません。しばらくは自分の陣地でゆっくりしてコンパイルが終わるのを待ちましょう。コンパイルが終わってFPS(Frame Per Second)が出てきました。ようやく本当のゲーム開始です。
そこで相手の攻撃を読み、侵攻して、草むらに潜み、相手がくるの待ち受けます。いざ相手へ攻撃をかけようとした瞬間、3に起因するコードの再コンパイルが発生し、画面がプチフリーズ。ゲームに復帰したら、目の前には銃を構える敵が…
こういう状況を避けるためにも、上述したような問題に対する回避策が求められました。それがAOTとasm.jsでした。AOTによって1,2の問題を回避し、その実現と3の回避のために型情報のふくまれたasm.jsが導入されることとなりました。
次回はasm.jsがどのように型情報を与えていくのか、型アノテーションを中心に解説します。
